技术博客
小葵API服务 AI 技术博客 - 最新的 AI 模型资讯、API 使用教程与行业动态
小葵API服务 的 AI API 使用建议
小葵API服务 面向需要 OpenAI 兼容接口、Claude/Gemini/GPT 多模型切换、包月额度管理和图像模型调用的用户。阅读本文后,可以结合本站的模型清单、独立使用文档和个人面板,把教程内容直接落到实际调用流程中。
标签:大模型基准测试
清除
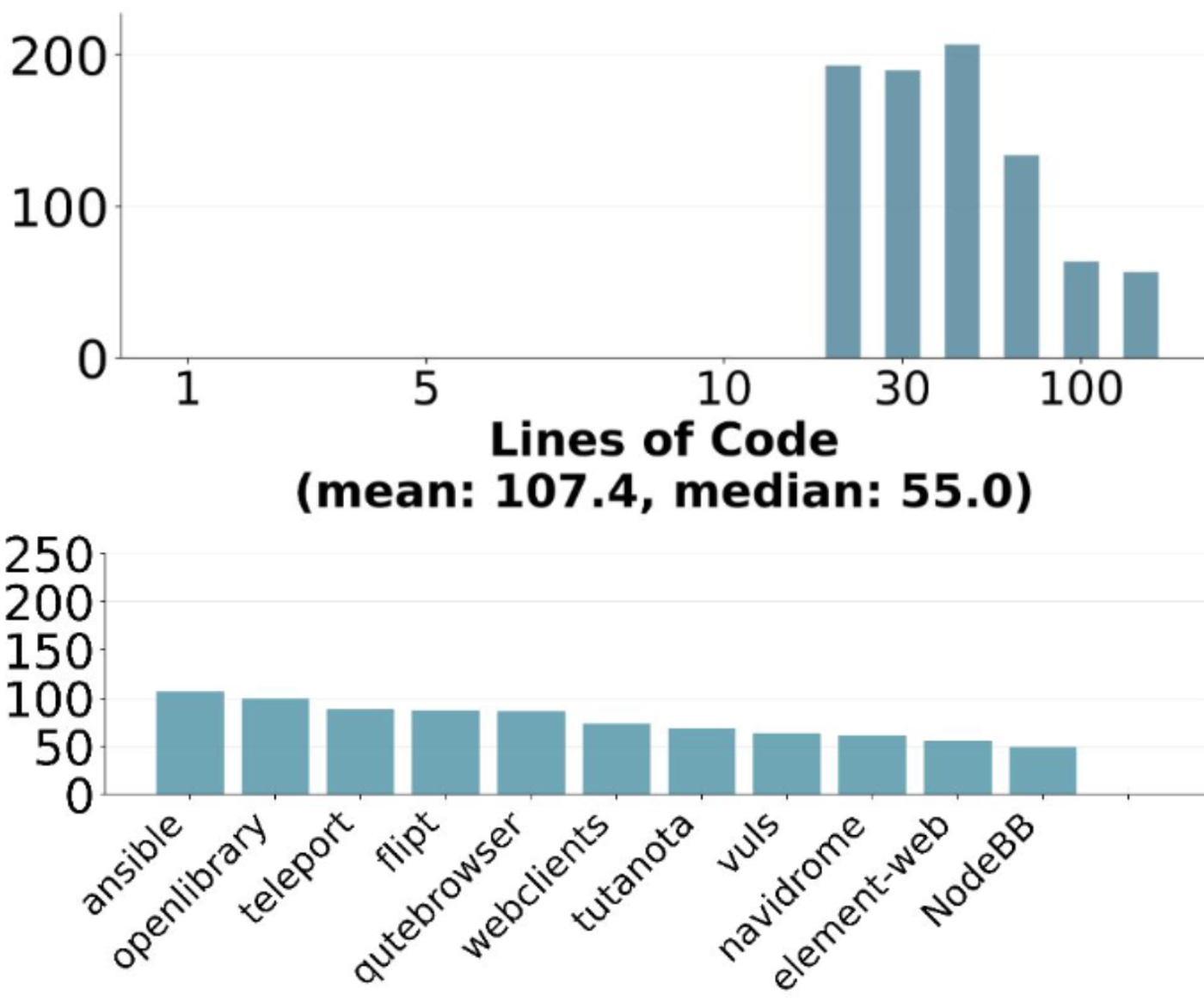
重新定义AI编码基准:SWE-Bench Pro 如何成为大模型的“真实战场”?
随着AI编程智能体的快速进化,传统的基准测试已逐渐失效。本文深度解析全新的 SWE-Bench Pro 基准测试,探讨为何顶尖模型在此遭遇“滑铁卢”,以及 Qwen、GPT-5 等模型在真实软件工程环境下的真实战力。

深度解析 Claude Opus 4.7:AI 编码智能体的全新里程碑及其“隐藏代价”
Claude Opus 4.7 于 2026 年 4 月发布,凭借 SWE-bench Verified 87.6% 的惊人成绩再次刷新 AI 编码极限。本文深度拆解其四大核心变化、视觉能力飞跃以及分词器调整带来的实际成本变动。
Claude Opus 4.7 深度评测:2026年编程智能体的性能天花板与隐形成本
Anthropic 正式发布 Claude Opus 4.7,SWE-bench Verified 评分飙升至 87.6%。本文深度解析其在自动编程、自我验证行为及视觉能力上的重大升级,并揭秘分词器更新带来的真实成本变动。
2026 AI 编程模型深度评测:从 SWE-bench 到 SWE-bench Pro,谁才是最强 AI 程序员?
随着 AI 编码技术的飞速发展,传统的基准测试已难以衡量顶尖模型的真实实力。本文深入分析最新的 SWE-bench 及 SWE-bench Pro 排行榜,对比 GPT-5.4、Claude Opus 4.6 等主流模型,揭秘 AI 代理在真实软件工程挑战中的表现。